This write-up outlines a simple, robust serialization system. The write-up uses C for its code examples, but the format and general implementation can be applied to any general-purpose language.
The system as outlined here, although simple, is the result of many iterations over several years. Note there are many "improvements" that could be made to this system, both in performance and reductions in size of the resultant data (eg. variable-sized integers, fixed-type arrays) — the system deliberately compromises on being "clever" for the sake of keeping things simple, though the user is free to make both additions in complexity and addition of base types, depending on how valuable those additions might be to their specific use-case.
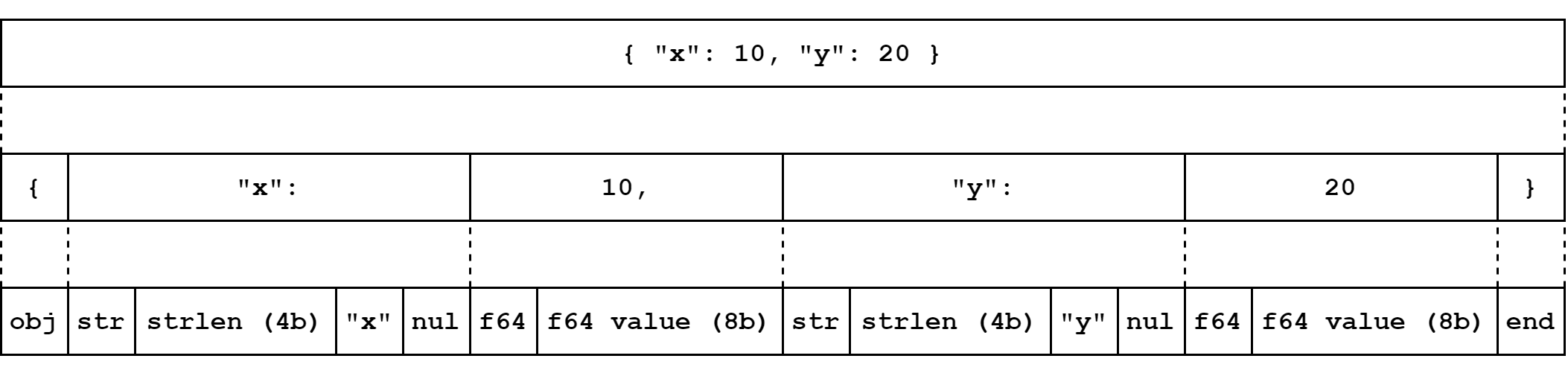
The serialization system:
string => offset if we choose to intern our strings).The system stores the data as a contiguous series of values. Each value consists of a "tag" byte representing the value’s type, followed by the data of the value. Thus something like a 64bit float would be stored as 1 byte with the enum TYPE_F64, followed by 8 bytes storing the float value itself.
Strings are stored as the tag byte, an integer representing the length of the string and the string data; the string is always followed by a single "null" byte — this is done to simplify things when working with C; since the data is always read from memory it allows us to use the strings directly while without copying them during the reading process — the zero-byte can be omitted if the data is intended to be used only with languages which do not use null-terminated strings.
In addition to scalar values and strings, the format supports arrays and objects. Arrays and objects work the same: a tag byte indicating either TYPE_ARRAY or TYPE_OBJECT followed by the contained values and a single tag byte of TYPE_END to indicate the end of the array/object. The only distinction between an array and object is in that arrays store a series of values (eg. value, value, value, etc.), where as an object stores a series of pairs of values (eg. key, value, key, value, key, value, etc.). Although both arrays and objects effectively work the same and we could make do using only arrays, two distinct types are used mainly to make things clearer when inspecting the data.
To give you an idea of what the serialization system might look like when implemented, below shows how one might write functions to serialize and deserialize a Rect struct using the system described in this write-up:
typedef struct {
double x, y, w, h;
} Rect;
void write_rect(Writer *w, Rect r) {
write_object(w);
write_string(w, "x"); write_f64(w, r.x);
write_string(w, "y"); write_f64(w, r.y);
write_string(w, "w"); write_f64(w, r.w);
write_string(w, "h"); write_f64(w, r.h);
write_end(w);
}
void write_rects(Writer *w, Rect *rects, int count) {
write_array(w);
for (int i = 0; i < count; i++) {
write_rect(w, rects[i]);
}
write_end(w);
}
Rect read_rect(Reader *r, Value obj) {
Rect res = {0};
Value key, val;
while (iter_object(r, obj, &key, &val)) {
assert(key.type == TYPE_STRING);
/**/ if (!strcmp(key.s, "x")) { res.x = val.f; }
else if (!strcmp(key.s, "y")) { res.y = val.f; }
else if (!strcmp(key.s, "w")) { res.w = val.f; }
else if (!strcmp(key.s, "h")) { res.h = val.f; }
}
return res;
}
// reads up to `max_count` rects into the `rects` array and returns the number
// of rects read — note: if you have a dynamic array as part of your base
// library, it could be used here instead of the fixed `rects` array
int read_rects(Reader *r, Value arr, Rect *rects, int max_count) {
Value val;
int i = 0;
while (iter_array(r, arr, &val) && i < max_count) {
rects[i] = read_rect(r, val);
i++;
}
return i;
}
Note that the use of macros (or, in other languages reflection) are not present in the above code. I’ve found that doing this tends to be detrimental; although the code seems verbose at a glance, it has the advantage of being mind-numbingly simple and immediately understandable at first glance. Additionally since the serialization of everything is fully explicit we can manually handle backwards compatibility explicitly and trivially.
An argument could be made that the code being this way could be more prone to typos or copy-paste errors, but, since the format is easy to inspect (see the below section) we can easily verify the code works correctly by dumping the result to plain text.
Due to the nature of the format, at its base the writer needs no state other than a buffer or file handle of which to write to (Note: additional state is required for string interning; see the String Interning section below).
typedef struct {
FILE *fp;
} Writer;
The writer is implemented in a single function of two arguments: the Writer context above, and a single value represented as a tagged union:
enum {
TYPE_ERROR,
TYPE_END,
TYPE_OBJECT,
TYPE_ARRAY,
TYPE_F64,
TYPE_BOOL,
TYPE_STRING,
};
typedef struct {
uint8_t type;
union {
struct { char *s; uint32_t len; };
double f;
bool b;
int depth;
};
} Value;
void write(Writer *w, Value val) {
// write tag byte
fwrite(&val.type, 1, 1, w->fp);
// write value
switch (val.type) {
case TYPE_F64:
fwrite(&val.f, sizeof(val.f), 1, w->fp);
break;
case TYPE_STRING:
fwrite(&val.len, sizeof(val.len), 1, w->fp); // write length
fwrite(val.s, 1, val.len, w->fp); // write string
uint8_t null = 0;
fwrite(&null, 1, 1, w->fp); // write null-terminator
break;
case TYPE_BOOL:
fwrite(&val.b, 1, 1, w->fp);
break;
}
}
Note that it’s a good idea to wrap the write function with helper functions for each type to ensure proper type checking to avoid accidentally setting the tag field to the wrong type for the data being written:
void write_f64(Writer *w, double f) {
write(w, (Value) { .type = TYPE_F64, .f = f });
}
void write_bool(Writer *w, bool b) {
write(w, (Value) { .type = TYPE_BOOL, .b = b });
}
void write_string(Writer *w, char *str) {
write(w, (Value) { .type = TYPE_STRING, .s = str, .len = strlen(str) });
}
void write_object(Writer *w) {
write(w, (Value) { .type = TYPE_OBJECT });
}
void write_array(Writer *w) {
write(w, (Value) { .type = TYPE_ARRAY });
}
void write_end(Writer *w) {
write(w, (Value) { .type = TYPE_END });
}
The union itself may seem redundant with the presence of the wrapper functions but the same union will be used by the reader, creating a nice parity between the write function and the read function below.
An example of how we would use the writer implemented in this section can be seen in the above Usage section.
The reader, at its core, consists of a single read function used to read a single value as a tagged union. Since we serialize strings with a null terminator the union returns a pointer directly to the serialized data, the string itself can be used directly without copying. If a read error occurs (such as an unknown tag, early end-of-file or out-of-bounds string length), a value with the type TYPE_ERROR is returned.
typedef struct {
char *data;
int len;
int cur;
int depth;
} Reader;
bool safe_read(Reader *r, void *dst, int size) {
int idx = r->cur + size;
if (idx > r->len) { return false; }
if (dst) { memcpy(dst, &r->data[r->cur], size); }
r->cur = idx;
return true;
}
Value read(Reader *r) {
Value res;
// read type
bool ok = safe_read(r, &res.type, 1);
// read value
switch (res.type) {
case TYPE_END:
r->depth--;
break;
case TYPE_OBJECT:
case TYPE_ARRAY:
r->depth++;
res.depth = r->depth;
break;
case TYPE_F64:
ok &= safe_read(r, &res.f, sizeof(res.f));
break;
case TYPE_BOOL:
ok &= safe_read(r, &res.b, 1);
break;
case TYPE_STRING:
ok &= safe_read(r, &res.len, sizeof(res.len));
res.s = &r->data[r->cur];
ok &= safe_read(r, NULL, res.len);
uint8_t null;
ok &= safe_read(r, &null, 1);
ok &= (null == 0);
break;
default: // bad type
ok &= false;
}
// return value, or error if anything above failed
return ok ? res : (Value) { .type = TYPE_ERROR };
}
Although all the data could be read manually using only the read function, two additional iterator functions are provided: one for objects and one for arrays. These iterator functions not only save us some code, but also keep track of whether we left a value unread (for example, an unknown key/value pair serialized from a later version of our application), and more importantly, if so, skips to the next value.
Skipping of values is achieved by maintaining a depth value. The Reader itself keeps track of its current depth — that is, an integer representing the current level of nesting — for example, if our current read state was within an object contained within an array, the depth would be 2, one increment for the array and another for the object. Once we reached the next end value (indicating the end of the object), the depth would decrement to 1.
Object and array values returned by the read function store their depth and are passed to the iterator function with each iteration — thus, if during iteration we skip a value which happens to be an object or array itself, the iterator will continue to read until the depth level returns to match that of the thing we are iterating, assuring we skip the unhandled data in its entirety.
void discard_until_depth(Reader *r, int depth) {
Value v = { .type = TYPE_END };
while (v.type != TYPE_ERROR && r->depth != depth) {
v = read(r);
}
}
bool iter_object(Reader *r, Value obj, Value *key, Value *val) {
discard_until_depth(r, obj.depth);
*key = read(r);
if (key->type == TYPE_END) { return false; }
*val = read(r);
return true;
}
bool iter_array(Reader *r, Value arr, Value *val) {
discard_until_depth(r, arr.depth);
*val = read(r);
return val->type != TYPE_END;
}
Refer to the Usage section above for examples on how the iterator functions are used.
Inspection is an important part of serialization; being able to inspect the data allows you to verify it is correct and gives you a better view of what is going on. Beyond verification it allows you to use existing text diffing tools to compare two states of serialized data. Suppose, while developing an application, you made a change to a document which resulted in some weirdness that you couldn’t explain — being able to quickly and easily see a text diff between the current version and an earlier working version of the document would prove invaluable.
Since the format is self-describing we can, with very little code or effort, write a means of converting the data to human-readable text:
void print_indent(int depth) {
for (int i = 0; i < depth; i++) {
printf(" ");
}
}
void print_value(Reader *r, Value val, int depth) {
Value k, v;
int count = 0;
switch (val.type) {
case TYPE_OBJECT:
printf("{\n");
while (iter_object(r, val, &k, &v)) {
if (count++ > 0) { printf(",\n"); }
print_indent(depth + 1);
print_value(r, k, depth + 1);
printf(": ");
print_value(r, v, depth + 1);
}
if (count > 0) { printf("\n"); }
print_indent(depth);
printf("}");
break;
case TYPE_ARRAY:
printf("[\n");
while (iter_array(r, val, &v)) {
if (count++ > 0) { printf(",\n"); }
print_indent(depth + 1);
print_value(r, v, depth + 1);
}
if (count > 0) { printf("\n"); }
print_indent(depth);
printf("]");
break;
case TYPE_F64:
printf("%.14g", val.f);
break;
case TYPE_BOOL:
printf(val.b ? "true" : "false");
break;
case TYPE_STRING:
printf("\"");
for (int i = 0; i < val.len; i++) {
if (val.s[i] == '"') {
printf("\\\"");
} else {
printf("%c", val.s[i]);
}
}
printf("\"");
break;
default: // bad type
printf("!!!ERROR!!!\n");
return;
}
}
And when used with the array of rectangles serialized in the Usage section:
Value rects_array = read(&r);
print_value(&r, rects_array, 0);
printf("\n");
The following output is produced:
[
{
"x": 1,
"y": 2,
"w": 3,
"h": 4
},
{
"x": 5,
"y": 6,
"w": 7,
"h": 8
},
{
"x": 9,
"y": 10,
"w": 11,
"h": 12
}
]
When storing many objects (and thus many strings which are typically identical) a small trade-off to simplicity can be made by support string interning; the complexity of this change only affects the writer, the cost to the reader is minimal.
To support string interning a new type would have to be added: TYPE_STRINGREF, in addition the reader would have to manage a mapping of written-strings to integer offsets in the file. When writing a string, the map would be checked to see if we had written it before, if so instead of writing a string we would write the TYPE_STRINGREF tag followed by the offset of the string in the file. If the string does not exist in the mapping we would write the string normally and add it to the map.
When reading, if a TYPE_STRINGREF was encountered, we would jump to the offset proceeding the tag byte and continue on with the string handling code, returning a TYPE_STRING value to the user. When reading the user would never handle the TYPE_STRINGREF value directly.